How z.ai Found and Fixed Race Condition Bugs Hidden in AI Inference at Scale
A deep dive into the KV cache bugs that only appeared under production load, and what every AI developer should know about inference infrastructure.
How z.ai Found and Fixed Race Condition Bugs Hidden in AI Inference at Scale
When a large language model starts producing garbled output, most developers assume the model is at fault. Maybe the context window is too long. Maybe there's a quality degradation issue. But a recent post from the z.ai team reveals a different reality: sometimes the bugs aren't in the model at all — they're buried in the infrastructure layer underneath it.
This post covers what the z.ai engineering team discovered while running GLM-5 at scale for complex coding agent tasks, and what it means for anyone building production AI systems.
What Is "Scaling Pain"?
The z.ai team coined the term Scaling Pain to describe the operational challenges that emerge when inference infrastructure hits its limits under real-world load. As coding agents move beyond simple dialogue and into long-horizon tasks — reading repos, planning refactors, writing tests across thousands of tokens — the infrastructure压力 (pressure) becomes unlike anything the industry has had to debug before.
The team serves hundreds of millions of coding agent requests per day. At that scale, a bug that affects 3-5 requests per 10,000 still means thousands of broken outputs every hour.
The Three Symptoms Nobody Could Reproduce
Starting in March 2026, GLM-5 users began reporting three types of abnormal outputs:
- •Garbled output — tokens that don't form coherent words
- •Repetition loops — the model getting stuck in the same phrase
- •Rare-character generation — Unicode characters that shouldn't appear
The first instinct was model quality degradation. But the z.ai team quickly ruled that out: the behavior wasn't reproducible for specific inputs. If it were a model problem, the same input would produce the same bad output every time. Instead, the anomalies appeared to correlate with system pressure and runtime state — pointing squarely at the inference infrastructure.
The Hardest Part: You Can't Reproduce It Locally
The most honest part of the z.ai post is this: they tried to reproduce the bugs by replaying user-reported cases locally, hundreds of times. Nothing.
The anomalies only became reproducible when they adjusted the Prefill-Decode disaggregation ratio and deliberately created conditions simulating peak-time Prefill backlog and Decode-side KV Cache pressure.
This is the reality of distributed systems bugs at scale: the failure mode only exists under production load. Your local environment is a lie.
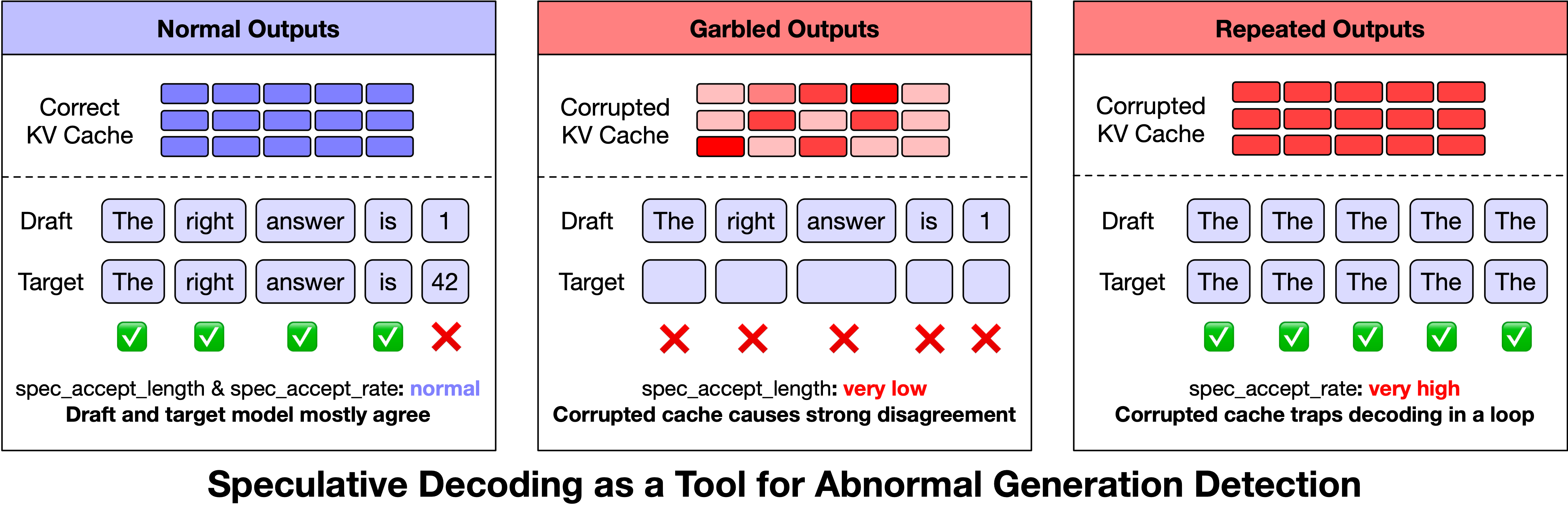
Finding Signals in Speculative Decoding Metrics
One of the most interesting discoveries in the post is how z.ai accidentally found a monitoring technique. Speculative decoding — a performance optimization where a draft model proposes candidate tokens and the target model verifies them — turned out to emit useful anomaly signals.
When they examined speculative decoding metrics during failed outputs, they noticed:
- •Acceptance rate dropped to near zero — the draft and target KV caches had diverged completely
- •Acceptance confidence spiked abnormally — the attention pattern degenerated into a high-confidence repetition loop
They turned this into an online monitoring strategy. When the acceptance rate stayed below 1.4 after 128 generated tokens, or confidence exceeded 0.96, the system proactively terminated the request and retried it on a different node.
This extended speculative decoding from a pure performance technique into a real-time output quality monitor.
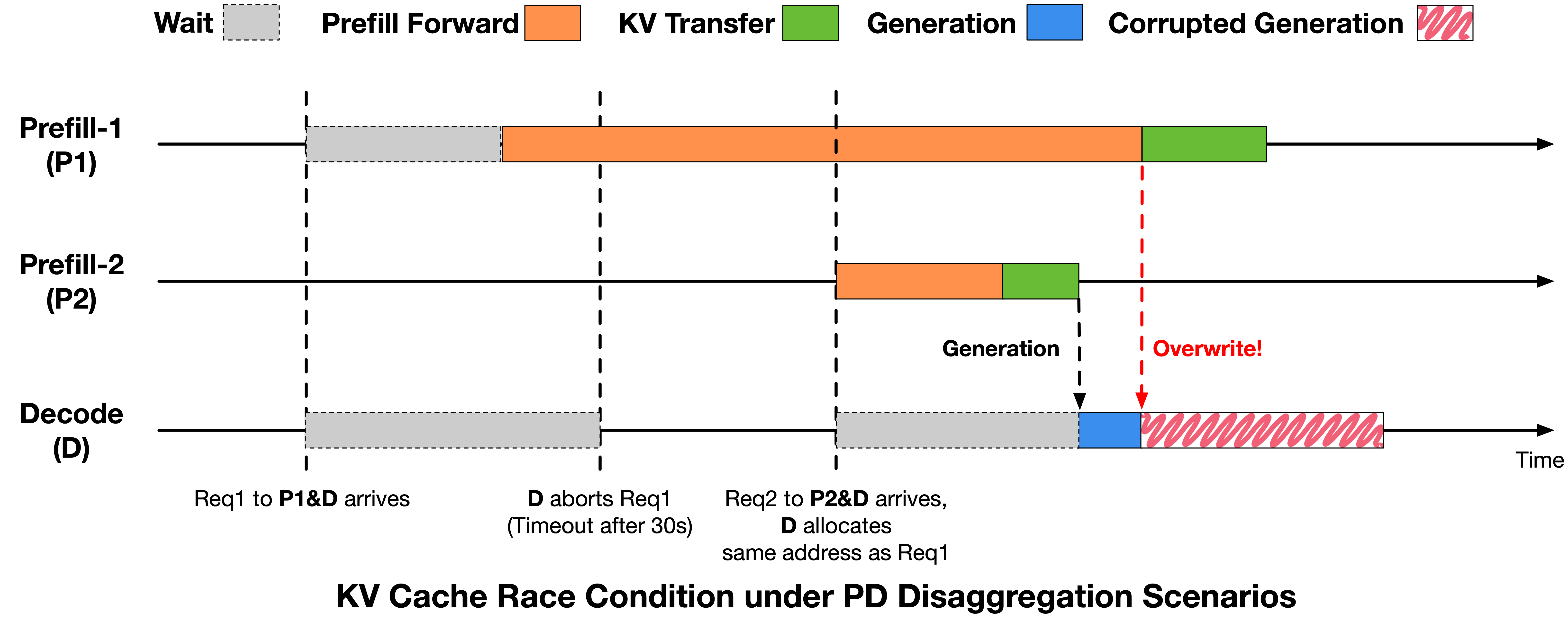
Bug #1: The KV Cache Reuse Race
After establishing that the bugs correlated with system pressure, the team traced the root cause to a KV Cache reuse conflict in their Prefill-Decode disaggregated architecture.
Here is what was happening:
1. Request A times out waiting for its Prefill stage to complete
2. The Decode side hits its timeout, aborts Request A, and reclaims its KV Cache memory
3. Request B arrives and is assigned to the same memory addresses that belonged to Request A
4. Request B's Prefill completes quickly — it was ready — and Decode begins generation
5. Meanwhile, Request A's in-flight KV Cache writes (issued before the abort) are still traveling over RDMA
6. These writes overwrite portions of Request B's KV Cache
Result: Request B reads corrupted KV data during decoding and produces garbled output. The bug looked like a model problem. It was actually a race condition in the request lifecycle.
The fix was explicit synchronization: before the Decode side reclaims any KV Cache slot, it must wait for all in-flight RDMA writes from the Prefill side to complete. After this fix, the abnormal output rate dropped from ~0.1% to below 0.03%.
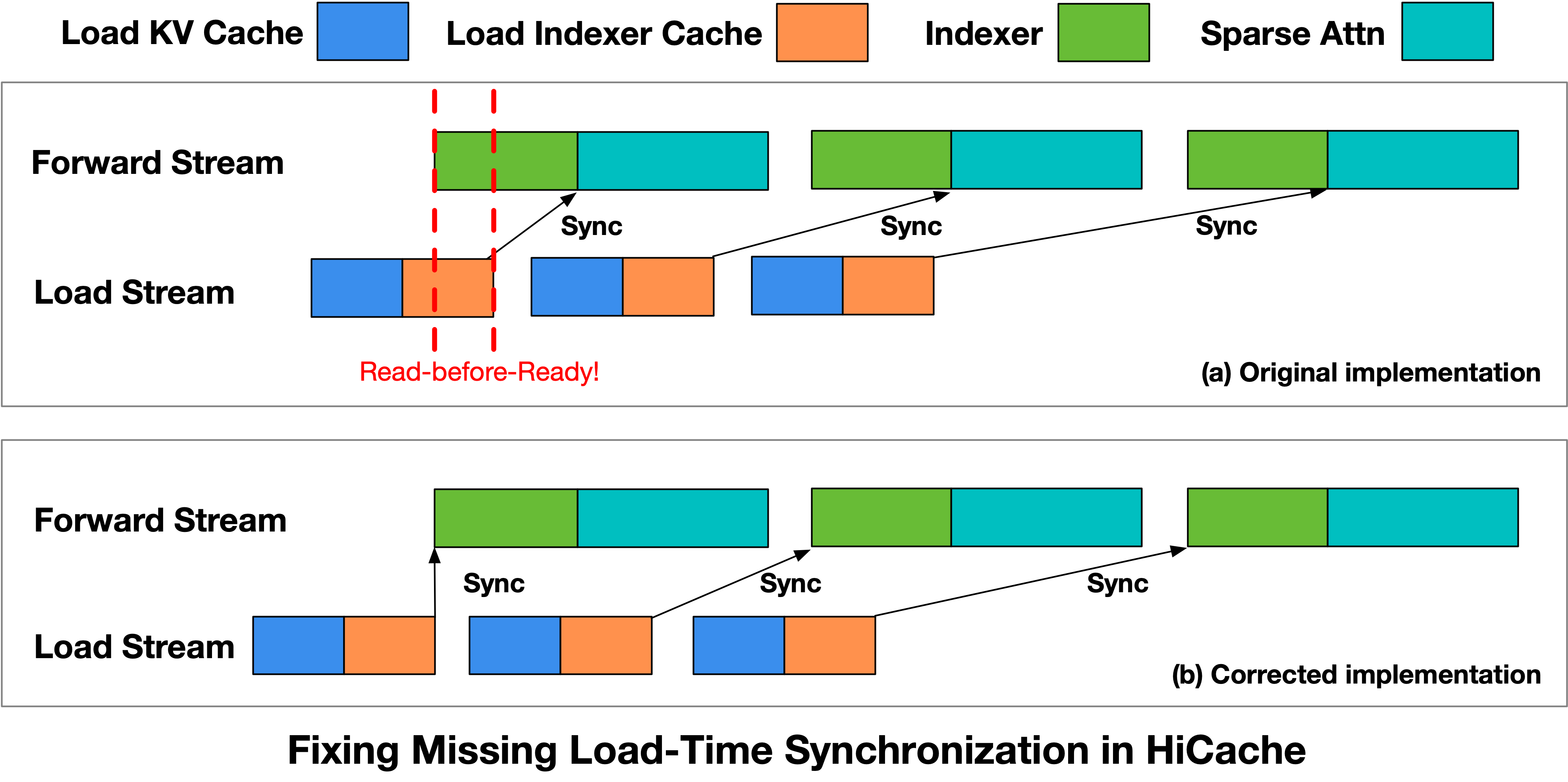
Bug #2: Read-Before-Ready in HiCache
The second bug involved Hierarchical KV Caching (HiCache) — a critical optimization for long-context coding workloads where input lengths average over 70,000 tokens.
The HiCache implementation uses separate streams: a Load Stream to swap KV Cache from CPU memory, and a Forward Stream to run index computation and sparse attention. The intent is to overlap data loading with computation for better throughput.
The problem: the Indexer kernel in the Forward Stream did not wait for the Load Stream to finish. It would begin execution before the KV Cache data was actually available in GPU memory.
The fix was explicit synchronization — inserting a wait point before the Indexer kernel launches, ensuring the data is ready before computation begins. The z.ai team submitted this fix to the SGLang community.
Why This Matters for Every AI Developer
The z.ai post is a case study in what happens when AI inference moves from toy demos to production scale. A few patterns worth noting:
The bugs weren't in the model. Every instinct would have pointed at model quality. The team had to systematically rule that out through careful experimentation.
The reproduction environment is hard to build. They needed to replicate production concurrency distribution and request timing locally. Most teams don't have this capability.
Monitoring at the infrastructure level is underinvested. The fact that speculative decoding metrics turned out to be an anomaly detector suggests there are many untapped signals in inference infrastructure that teams aren't capturing.
Open-source contribution as a byproduct. Rather than keeping the HiCache fix internal, z.ai submitted it to SGLang. This is the right move — inference infrastructure bugs at this level affect everyone building on these architectures.
What the Community Is Saying
This post resonated across the AI engineering community. On Hacker News, developers pointed out that these patterns — race conditions in cache coherence, async scheduling bugs — are the same classes of problems that haunted distributed databases and operating systems in the 1990s.
One commenter noted: "the real pain comes when these issues only surface in production, and by then the cost to refactor is immense."
Another observation: "AI made shipping easier. It didn't make durable product design easier."
The consensus: building AI applications in 2026 means accepting that the hard problems have moved from model architecture to inference infrastructure. The teams that invest in observability and stress testing at the systems level will be the ones running reliable AI products.
How to Monitor for Silent Failures
The z.ai post raises a practical question every AI developer should ask: how do you detect silent failures before users report them?
A few patterns that emerge from this case study:
1. Track infrastructure-level metrics alongside output quality — acceptance rates, cache hit ratios, timeout frequencies
2. Build canary workloads that simulate production load patterns, not just benchmark inputs
3. Monitor for statistical anomalies in output distributions — even if you can't define what a "good" output is, you can detect when outputs become unusual
4. Instrument speculative decoding if you're using it — it's a free anomaly signal
5. Test at scale before you need to — bugs that appear at 10,000 concurrent requests often don't exist at 100
The Takeaway
The z.ai Scaling Pain post is worth reading in full for anyone running LLM inference in production. It documents not just the specific bugs, but the methodology: systematic elimination, careful reproduction, and treating infrastructure as a first-class debugging concern.
As coding agents and long-context workflows become the dominant use case for LLMs, these infrastructure challenges will surface more often. The teams that understand that the model is usually not the problem will ship more reliable AI products.
Have you encountered similar infrastructure-level bugs in your AI systems? Share your experience with the NeuralStackly community.
Share this article
About NeuralStackly
Expert researcher and writer at NeuralStackly, dedicated to finding the best AI tools to boost productivity and business growth.
View all postsRelated Articles
Continue reading with these related posts
AI Agents in Production 2026: What Actually Breaks and How to Fix It
AI Agents in Production 2026: What Actually Breaks and How to Fix It
Real-world failures deploying AI agents in 2026. Tool calling loops, context truncation, permission escalation, and the patterns that actually hold up under load.

India AI Impact Summit 2026: $100B+ Deals Reshape Global AI Landscape
OpenAI, Anthropic, Google, and AMD announce major India investments totaling over $100 billion in AI infrastructure. The four-day summit draws 250,000 attendees including Sam Al...
AI Agents in Production: Complete Deployment Guide 2026
AI Agents in Production: Complete Deployment Guide 2026
Everything you need to know about deploying AI agents in production. Covering orchestration frameworks, monitoring, error handling, scaling strategies, and real-world case studi...

TurboQuant: The Memory Revolution That's Reshaping AI Economics in 2026
TurboQuant's PolarQuant + QJL algorithm delivers 6x memory reduction and 8x speedup with zero accuracy loss. Discover how this breakthrough is democratizing access to frontier A...
Gemini Embedding 2: Google Launches a Multimodal Embedding Model for Search and RAG
Gemini Embedding 2: Google Launches a Multimodal Embedding Model for Search and RAG
Google has launched Gemini Embedding 2, a new multimodal embedding model that can map text, images, audio, video, and documents into one shared semantic space. Here is what laun...